FCOS: Fully Convolutional One-Stage Object Detection
提出时间:2019年(iccv)
github上面star数目:2.8k
关键词:fully convolutional, one-stage, anchor-free, FPN, centerness
背景
使用Anchor(Box)的弊端:(典型的网络有SSD,RetinaNet)
1.太多hyperparam, 调试复杂
2.对于小型物体精确度不够高
3.通用性差
4.Negative sample占压倒性多数
5.IOU计算昂贵
因此提出问题:Can we solve object detection in the neat per-pixel prediction fashion,analogue to FCN for semantic segmentation?(我们能否用简单的逐像素预测方式来解决目标检测,类似于FCN进行语义分割?)(FCN特点:网络里面只有卷积层,没有全连接层,一个经典的应用就是图像分割)

上面的图显示的是逐像素进行预测的步骤,输出的图像经过一系列的操作得到和输入图像同样尺寸的feature map,其中每一个单元都会进行一个预测,比如预测这个单元处于哪个类别里面的。
内容/方法论
区域探索方法

feature map中的每个点都对应着输入图像中的一个点,坐标如上图中所示,其内容为对应着的输入图像的点到它所在的预测框的距离,分别为上下左右四个距离,所做的边框预测所做的就是这四个值。

完整架构
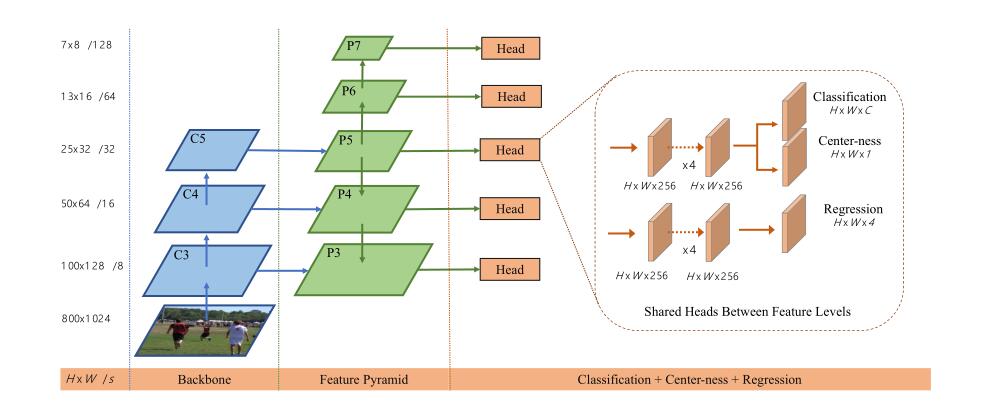
从p5到p6,p7:stride为2的conv
由此得出,从p3到p7,总的stride数分别为8,16,32,64,128


除了centerness外,B方案是让处于边框中心的单元归为positive,远离中心的归为negative
Loss function
用于类别分类的loss function: focal loss
用于边框回归的loss function: IOU loss
用于centerness的loss function: BCE loss
由于t=(l,t,r,b)的4个参数都为正数,所以在进行回归的时候,通过指数函数,将实数映射到正数上
训练环境
SGD,iter=90k, lr=0.01, lr/=10 at 60k & 80k
batch size=16, Weight decay =1e-4, momentum=0.9
实验与探索
1.FCOS的优势
proposal free + anchor free,减少了hyper-parameter
避免了IOU之类的复杂计算
模型精准度高
通用性高(extended to solve other vision tasks with minimal modification)
2.与RetinaNet的BPR(best possible recall)比较
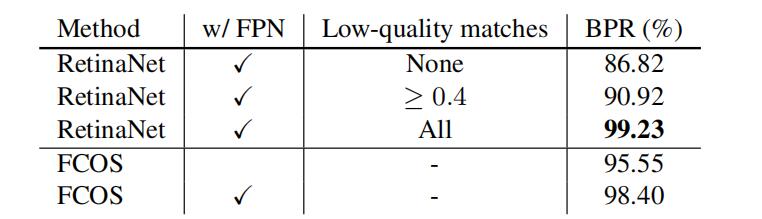
BPR可以看成是recall的上限,recall是越高越好,但是不代表recall越高模型就越精确
3.Ambiguous单元数量

Amb.samples为所有positive单元中的ambiguous单元
Amb.samples(diff.)为amb.samples中除去同处于一个重叠区并同处于一个类别下的单元,这些单元不会影响模型预测
结论:实际应用中ambigious的数量并不是很多
4.Centerness的影响

centerness+为通过边框regression来计算出来的centerness
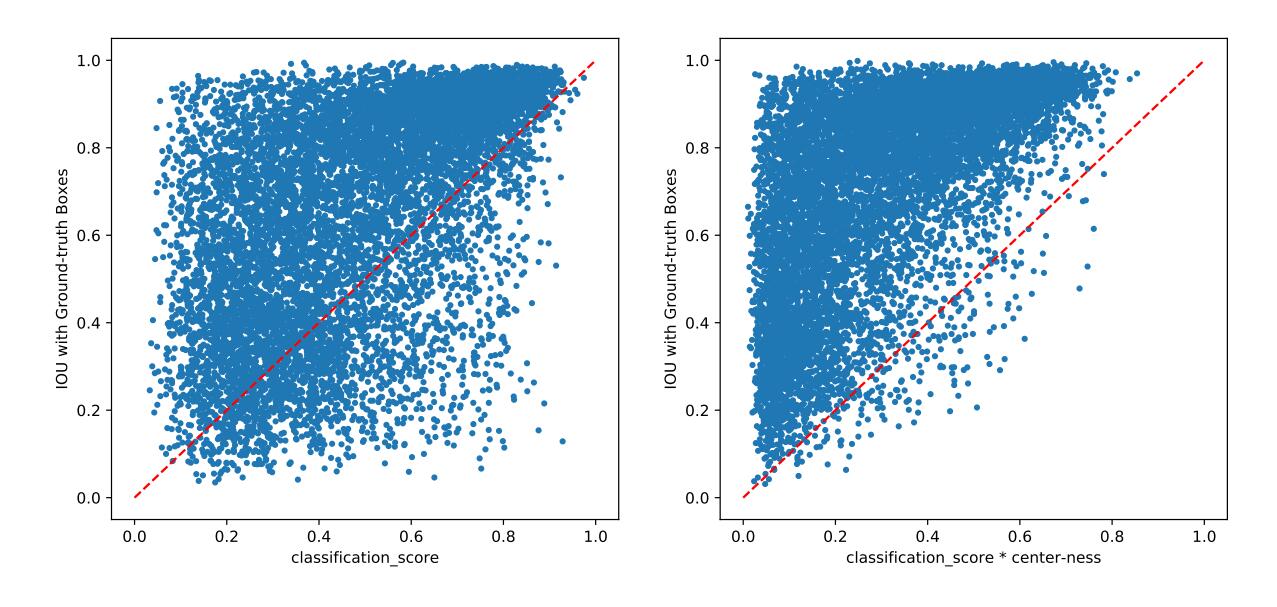
横坐标为得分,纵坐标为IoU
高得分但是IOU低意味着高概率是false-positive
5.继续对模型进行优化
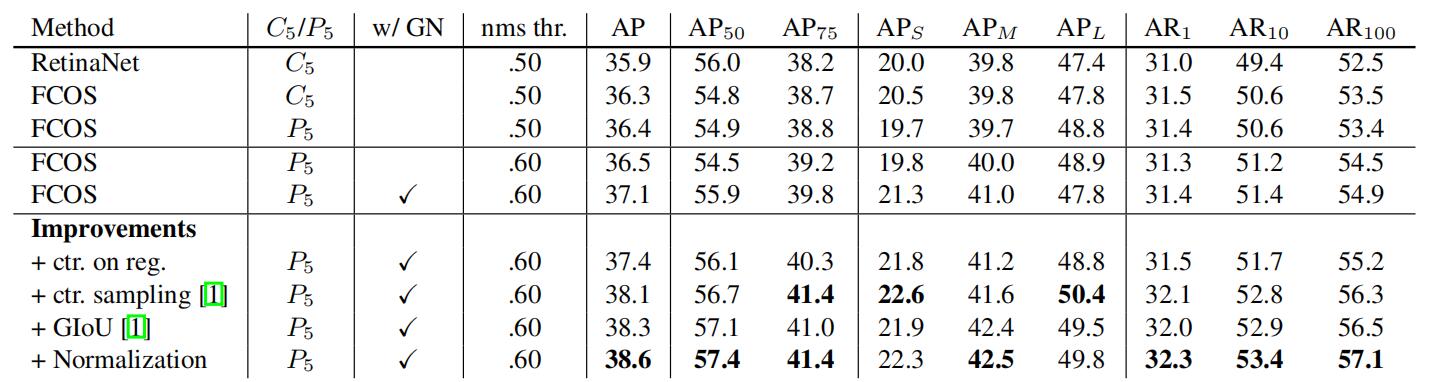
什么都不做的情况下,FCOS比起RetinaNet略好。下面是所做的优化:
1.C5/P5:用C5还是用P5来生成P6,P7两个层
2.w/GN:是否在除最后一层外的其他Conv层使用Group Norm
3.ctr on reg:将centerness分支移动到regression的那一个分支上
4.ctr sampling:上述B方案(处于中心的单元归为positive等)
5.GloU:GloU loss代替IoU loss
6.Normalization
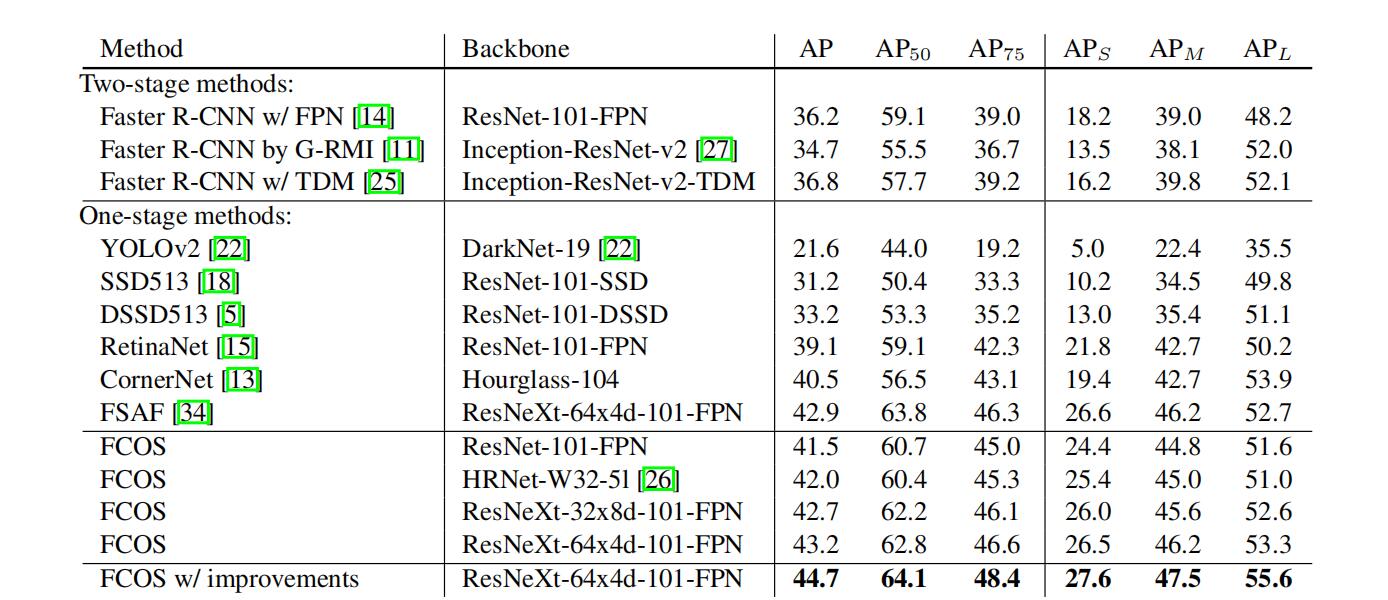
6.与其他OD模型的横向对比
7.PR曲线
3张图分别为IoU=0.5,0.75和0.9
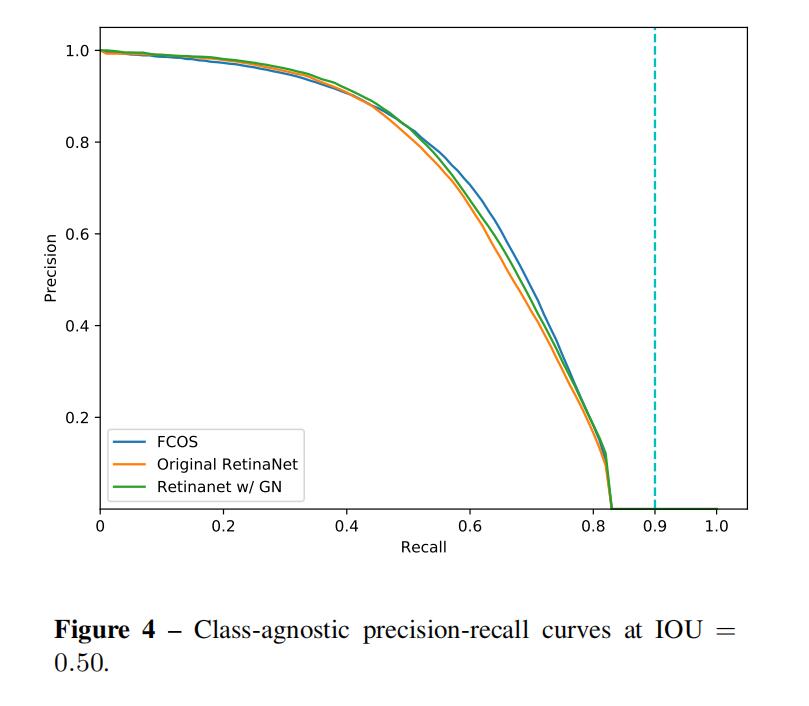
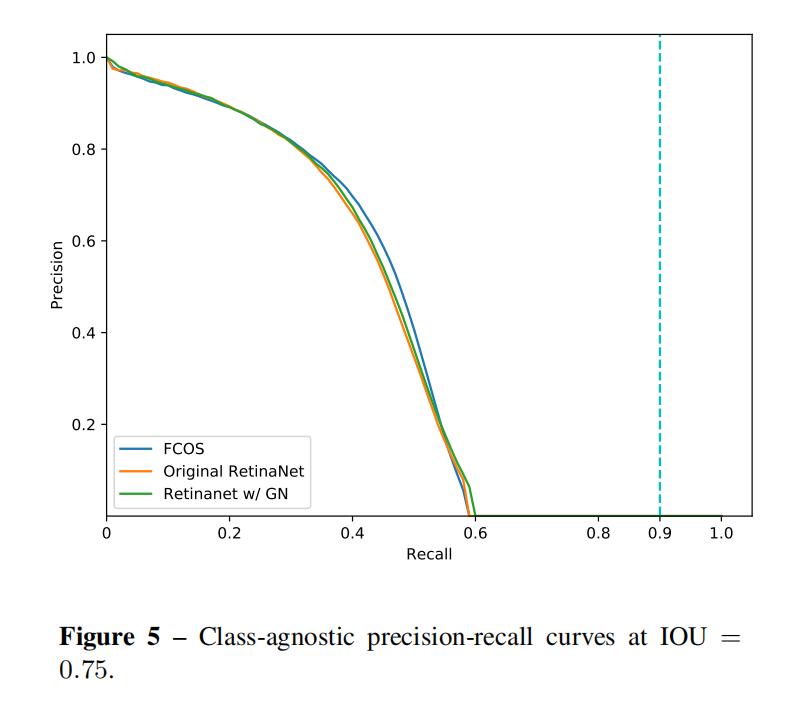
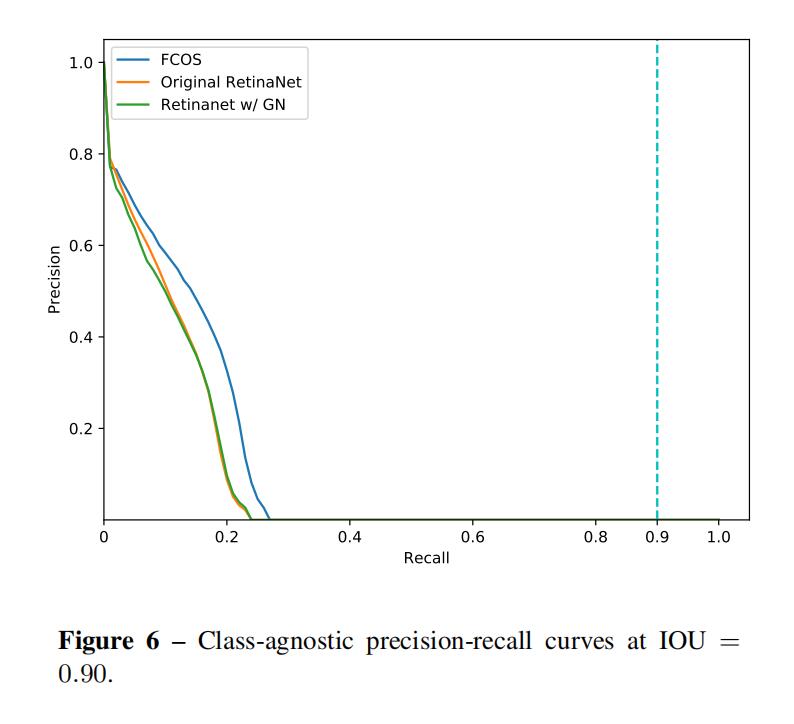
从图中可以看出,在IOU的值为0.5和0.75时,三种方法的曲线几乎是重合的,当IOU为0.9时,FCOS的效果要优于其他两种情况,论文中团队说是Retinanet的值很高,就会使positive的数据减少,最后影响模型的表现。
分类效果
