RNN浅谈
简介
首先,在了解循环神经网络之前我们应该确认自己是否需要一个专门用于处理信息序列的网络以及这些网络要实现哪些任务。
递归神经网络的优点在于其应用的多样性。当我们处理RNN时,他们具有处理各种输入和输出类型的强大能力。
-
情感分类 —这可以是将推文简单地分为正面和负面情绪的任务。因此,这里的输入将是不同长度的推文,而输出是固定类型和大小的。

-
图文字幕—这种情况我们只有一个输入图像,会产生一系列单词或者单词序列作为输出。这里的图像可能是固定大小的,但是输出是对不同长度的描述

-
语音翻译—利用RNN我们可以实现将汉语翻译成英语等功能,每种语言都有自己的语义,并且同一句子的长度会有所不同,因此,这里的输入和输出长度是变化的。
因此,RNN可以用于将输入映射到不同类型,长度的输出并且在其应用中相当通用。
什么是递归神经网络
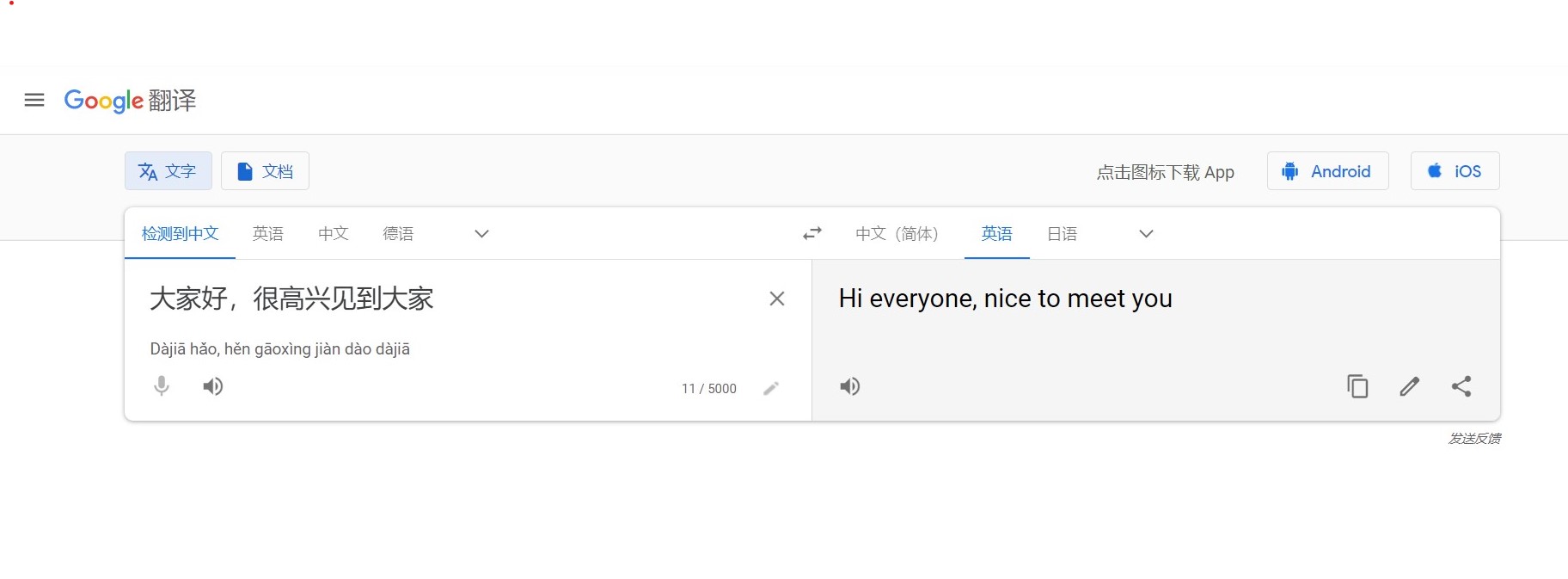
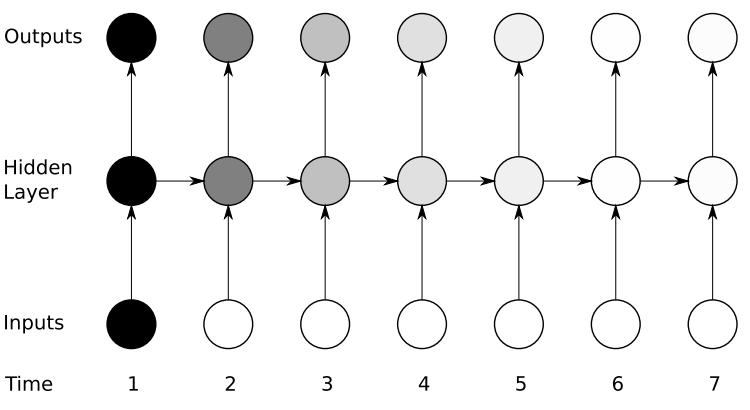
假设任务是预测句子中的下一个单词,以最简单的形式,我们有一个输入层,一个隐藏层和一个输出层。输入层接收输入,应用隐藏层激活,然后我们最终接收输出。
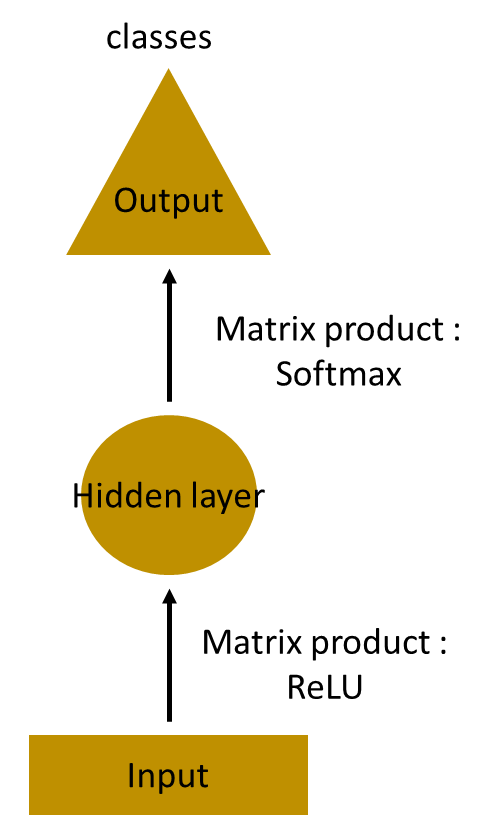
让我们有一个更深的网络,其中存在多个隐藏层。因此,在这里,输入层接收输入,首先应用隐藏层激活,然后将这些激活发送到下一个隐藏层,并通过这些层进行连续激活以产生输出。每个隐藏层都有自己的权重和偏差。
由于每个隐藏层都有自己的权重和激活,因此它们的行为独立。现在的目标是确定连续输入之间的关系。因此我们尝试将输入提供给隐藏层。
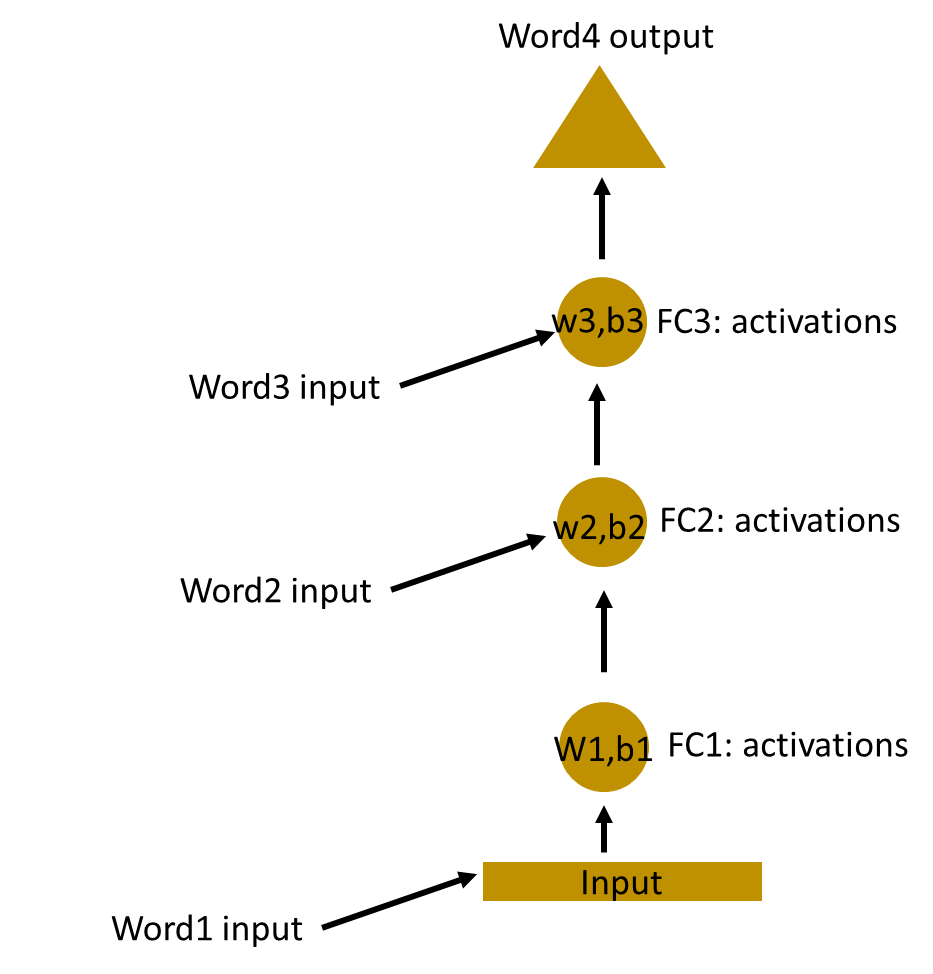
在这里,这些隐藏层的权重和偏差是不同的。因此,这些层中的每一层都是独立运行的,无法将其组合在一起。为了将这些隐藏层组合在一起,我们将对这些隐藏层具有相同的权重和偏差。
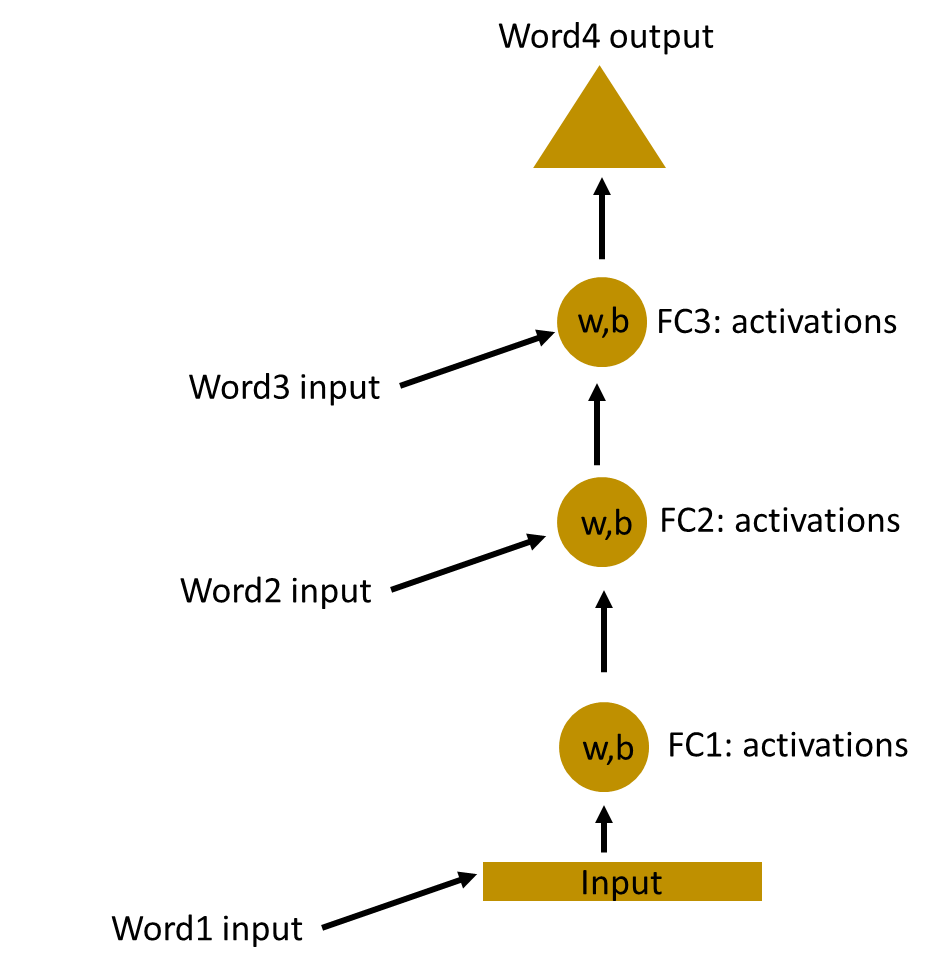
现在,我们可以将这些层组合在一起,以使所有隐藏层的权重和偏差相同。所有这些隐藏层都可以在单个循环层中一起滚动。

因此,就像将输入提供给隐藏层一样。在所有时间步长上,由于现在的单个神经元,递归神经元的权重将相同。因此,循环神经元存储先前输入的状态,并与当前输入组合,从而保留当前输入与先前输入的某种关系。
详细了解复发性神经元
首先让我们执行一个简单的任务。让我们以字符级RNN为例,其中有一个单词“ Hello”。因此,我们提供了前4个字母,即h,e,l,l,并要求网络预测最后一个字母,即“ o”。因此,这里的任务词汇只有4个字母{h,e,l,o}。在涉及自然语言处理的真实案例中,词汇表包括整个Wikipedia数据库中的单词,或一种语言中的所有单词。为简单起见,在这里我们只采用了很小的一组词汇。
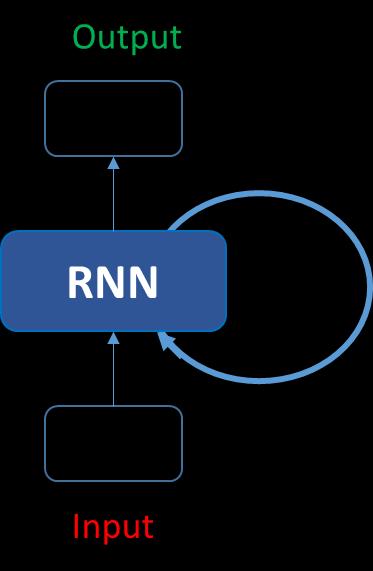
让我们看看如何使用以上结构预测单词“ hello”中的第五个字母。在上述结构中,蓝色RNN块将称为递归公式的内容应用于输入向量及其先前状态。在这种情况下,字母“ h”前面没有任何内容,让我们以字母“ e”为例。因此,在将字母“ e”提供给网络时,将递归公式应用于字母“ e”和之前的状态即字母“ h”。这些被称为输入的各种时间步长。因此,如果在时间t处输入为“ e”,那么在时间t-1处输入为“ h”。递归公式适用于e和h。我们得到一个新的状态。
当前状态的公式可以写成–
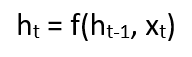
在此,Ht是新状态,ht-1是先前状态,而xt是当前输入。现在,我们有了前一个输入的状态,而不是输入本身,因为输入神经元会将变换应用于我们的前一个输入。因此,每个连续的输入都称为一个时间步。
在这种情况下,我们有四个输入要提供给网络,在递归公式期间,每个时间步都将相同的函数和相同的权重应用于网络。
以递归神经网络的最简单形式,假设激活函数为tanh,递归神经元的权重为Whh,输入神经元的权重为Wxh,我们可以将时间t处的状态方程写为–
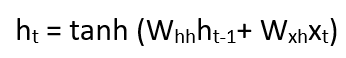
在这种情况下,循环神经元只是考虑了先前的状态。对于更长的序列,方程式可以包含多个这样的状态。一旦计算出最终状态,我们就可以继续产生输出
现在,一旦计算出当前状态,我们就可以将输出状态计算为:
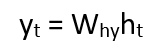
总结一下循环神经元中的步骤:
- 1 输入的单个时间步长被提供给网络,即xt被提供给网络
- 2 然后,我们使用当前输入和先前状态的组合来计算其当前状态,即我们计算ht
- 3 当前ht在下一时间步变为ht-1
- 4 我们可以根据问题的需要采取许多时间步骤,并结合之前所有状态的信息
- 5 完成所有时间步长后,将使用最终当前状态来计算输出yt
- 6 然后将输出与实际输出进行比较,并产生错误
- 7 然后将错误反向传播到网络以更新权重,并对网络进行训练
消失和爆炸梯度的问题
RNN根据信息的结果取决于其先前状态或先前n个时间步长这一事实进行工作。常规RNN可能难以学习远程依赖关系。例如,如果我们有一个句子,例如“吃我的披萨的男人的头发是紫色的”。在这种情况下,紫色头发的描述是给男人的,而不是披萨的。因此,这是一个长期依赖。
如果在这种情况下向后传播错误,则需要应用链式规则。要在相对于第一个时间步的第三时间步后计算误差,∂E/∂W=∂E/∂y3∂y3/∂h3∂h3/∂y2*∂y2/∂h1..并且存在长的依存关系。
在这里,我们应用链式法则,如果任何一个梯度接近0,由于相乘,所有梯度将以指数级速度快速趋于零。这样的状态将不再帮助网络学习任何东西。这被称为消失梯度问题。
与爆炸梯度问题相比,消失梯度问题更具威胁性,爆炸爆炸问题由于单个或多个梯度值变得很高而变得非常大。
消失梯度问题之所以引起更多关注,是因为可以通过将梯度剪切为预定阈值来轻松解决爆炸梯度问题。幸运的是,还有一些方法可以解决消失的梯度问题。诸如LSTM(长期短期记忆)和GRU(门控循环单元)之类的体系结构可用于解决梯度消失的问题。
其他RNN架构
如我们所见,当我们要求RNN处理长期依赖关系时,它们会遭受梯度消失的困扰。随着参数数量变得非常大,它们也变得非常难以训练。如果我们展开网络,它会变得如此庞大,以至于其融合是一个挑战。
长短期内存网络(通常称为“ LSTM”)是一种特殊的RNN,能够学习长期依赖关系。它们是由Hochreiter&Schmidhuber介绍的。它们在处理各种各样的问题上表现出色,现已被广泛使用。LSTM也具有这种链状结构,但是重复模块的结构略有不同。而不是只有一个神经网络层,而是有多层,它们以非常特殊的方式进行交互。它们具有输入门,忘记门和输出门。
另一种有效的RNN架构是门控循环单元,即GRU。它们是LSTM的变体,但结构更简单且易于训练。它们的成功主要归功于控制网络信号的门控网络信号,这些信号如何使用当前输入和先前的内存来更新当前激活并产生当前状态。这些门具有自己的权重集,这些权重集会在学习阶段进行自适应更新。我们这里只有两个门,重置是更新门。
新的RNN架构我还没有很好的了解,有时间会继续更新这两种RNN架构。