DRNN浅谈
单通道音乐人声分离
单通道音乐人声分离的目的是从一首歌曲中分离出人声和伴奏声。可以用m=s1+s2表示,其中m表示混合歌曲,s1和s2分别表示人声和伴奏声。单通道音乐人声分离的方法很多,比如非负矩阵分解,低秩稀硫矩阵分解以及基于基音周期检查的一些方法,但是这些方法的分离效果会比较差。利用DRNN来分离的话就能够取得很好的分离结果。因此我想主要介绍一下如何利用DRNN进行单通道音乐人声分离。
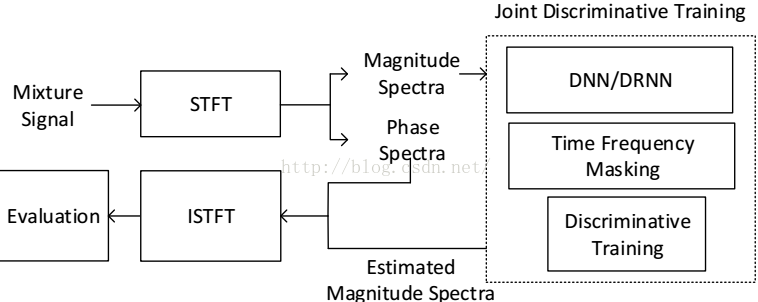
简要介绍一下该流程图。给定一首混合歌曲Mixture Signal,通过短时傅里叶变换得到混合歌曲的振幅谱和相位谱。混合歌曲的振幅谱通过分离模型(虚线框的内容),能分离出人声和伴奏声的振幅谱(Esitmated Magnitude Spectra)。分离出来的人声和伴奏声的振幅谱与混合歌曲的相位谱,经过短时逆傅里叶变换,分别得到分离后的人声和伴奏声波形谱。DNN/DRNN在单通道音乐人声分离中的主要内容是虚线框里的东西。其中的时频掩蔽(Time Frequency Masking)是人声分离中常用的技术,而Discriminative Training则是DNN/DRNN在训练人声分离模型中用到的损失函数。
在利用DNN/DRNN进行人声分离的时候,模型的输入是短时傅里叶变换后的一帧振幅谱,而输出两帧振幅谱并列成一个向量。如输入的帧的大小为512,则输出的大小为1024,前512个点是分离后的一帧人声振幅谱,后512个点是分离后的一帧伴奏声振幅谱。训练模型的时候,因为已经有纯净的人声和伴奏声作为监督数据,所以与其他利用神经网络解决有监督问题都是同一个原理的。只是我们的人声分离问题中,纯净的人声和伴奏声也需要进行短时傅里叶变换得到振幅谱。
接下来介绍DRNN的结构图
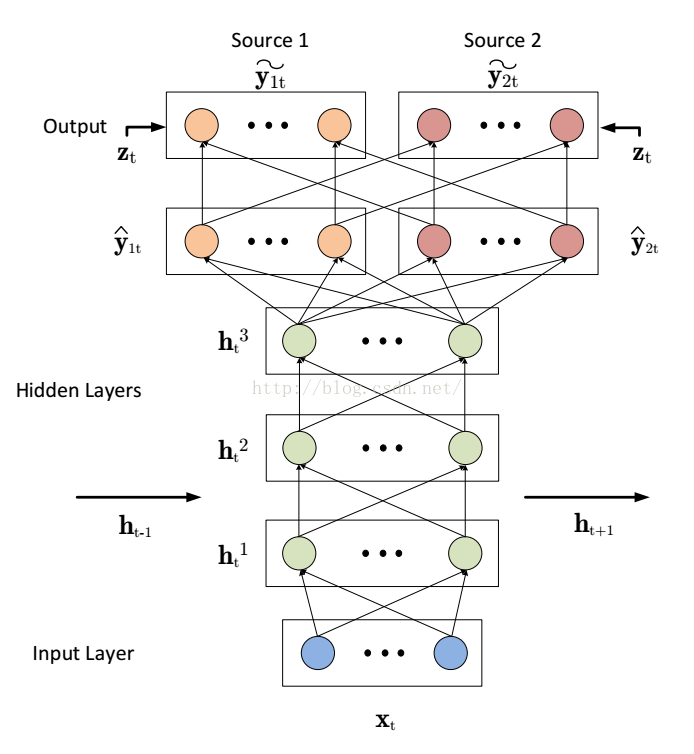
解释一下这个结构图。输入为Xt(混合歌曲的一帧或者多帧振幅普);输出有两层yt(1和2分别为人声和伴奏声),带尖号的是模型的真正输出,带波浪号的是经过时频掩蔽后的输出。在神经网络参数更新中尖号到波浪号之间是没有参数更新的。该神经网络有三层隐藏层,其中在第二层是有加入前一时刻的隐藏层信息的。关于这个模型结构的一些其他信息在下表可以看到:
时频掩蔽技术
上文提到了时频掩蔽技术由下面的公式给出:
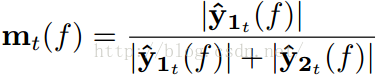
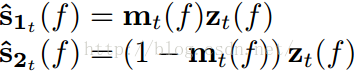
由上面的公式,可以知道,时频掩蔽的过程其实就是求每一个时频点中人声和伴奏声占混合歌曲的百分比,然后人声和伴奏声的占的百分比分别乘以混合信号,从而得到最后的分离振幅谱。DNN/RNN之所以能够有效分离出人声和伴奏声的一个关键点是,将时频掩蔽作为模型的层叠加到模型的原始输出层,并进行训练(其实并没有权值参数参与训练)。这样就限制了模型的每个输出点的值只能在模型的输入值之间。掩蔽技术可以说是对模型的一个约束吧。
损失函数
接下来我们简要分析一下DNN/RNN的损失函数,也就是一开始说的Discriminative Training。我们以简单的平方误差损失函数作为分析,该损失函数与上表中的损失函数的功能是一样的。Discriminative Training训练的损失函数如下:
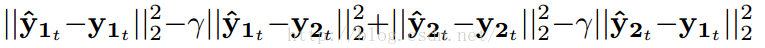
需要注意的是,这个损失函数模型输出是用尖号的y表示,但真正的训练时候其实是用上面提到的经过时频掩蔽后带波浪号的y的。上式中,y1t(尖角号)和y2t(尖角号)表示模型在时刻t(第t帧)的输出,没有带尖号的y则为纯净的人声和伴奏声。假设下标1代表人声,下标2代表伴奏。那么上式中的第一个平方误差的目的是让分离后的人声与纯净的人声越来与接近,第二个平方误差的目的是分离后的人声包含更少的伴奏声,第三个平方误差的目的是分离出来的伴奏声与纯净的伴奏声越来越接近,第四个平方误差则是使分离出来的伴奏声包含更少的人声。其中γ是一个常数项。
最终数据
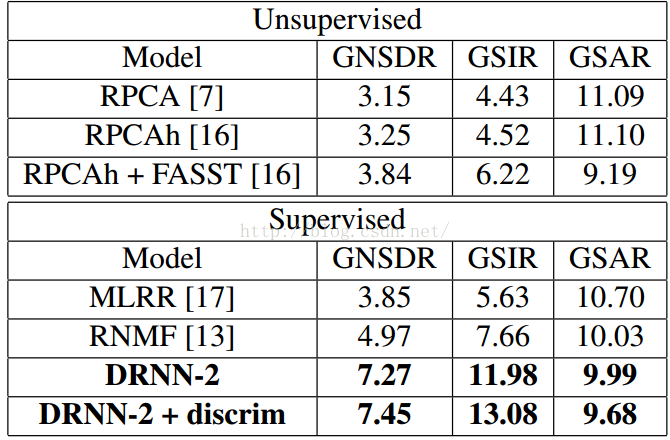
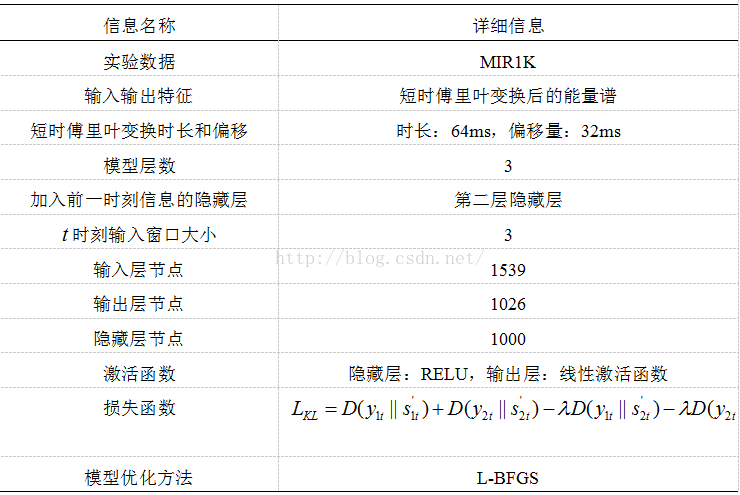
我读的论文中有很丰富的实验数据,主要是关于DRNN与DNN的对比,以及模型的一些参数选择,这边的这个表主要是比较DRNN与其他人声分离方法的性能。加粗的是DRNN的方法,很明显能够看出DRNN的性能还是很突出的(三个指标的值越大表示分离效果越好)。